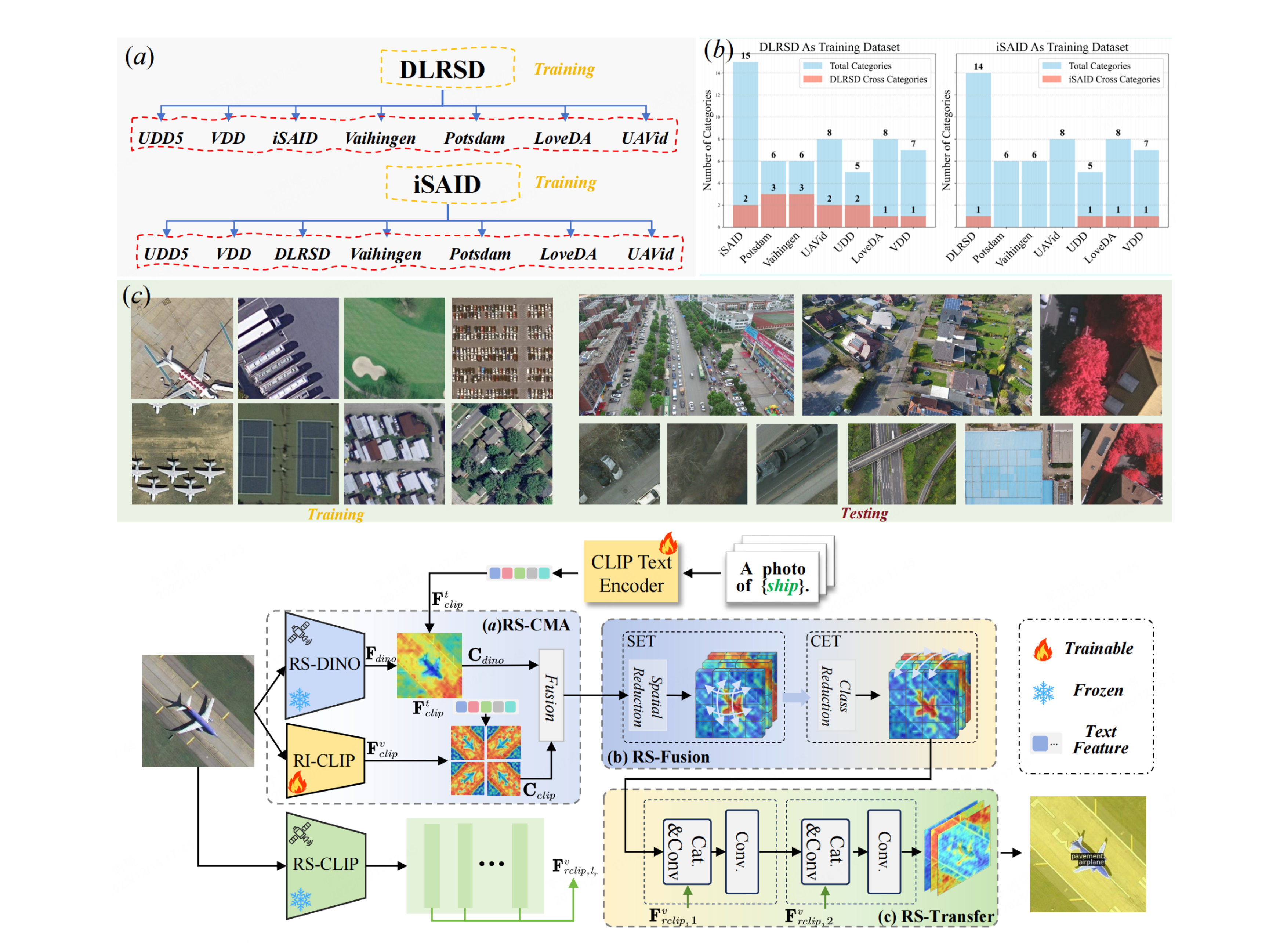
An Open-Source Benchmark and Baseline for Multi-temporal Referring Segmentation
arXiv 2026

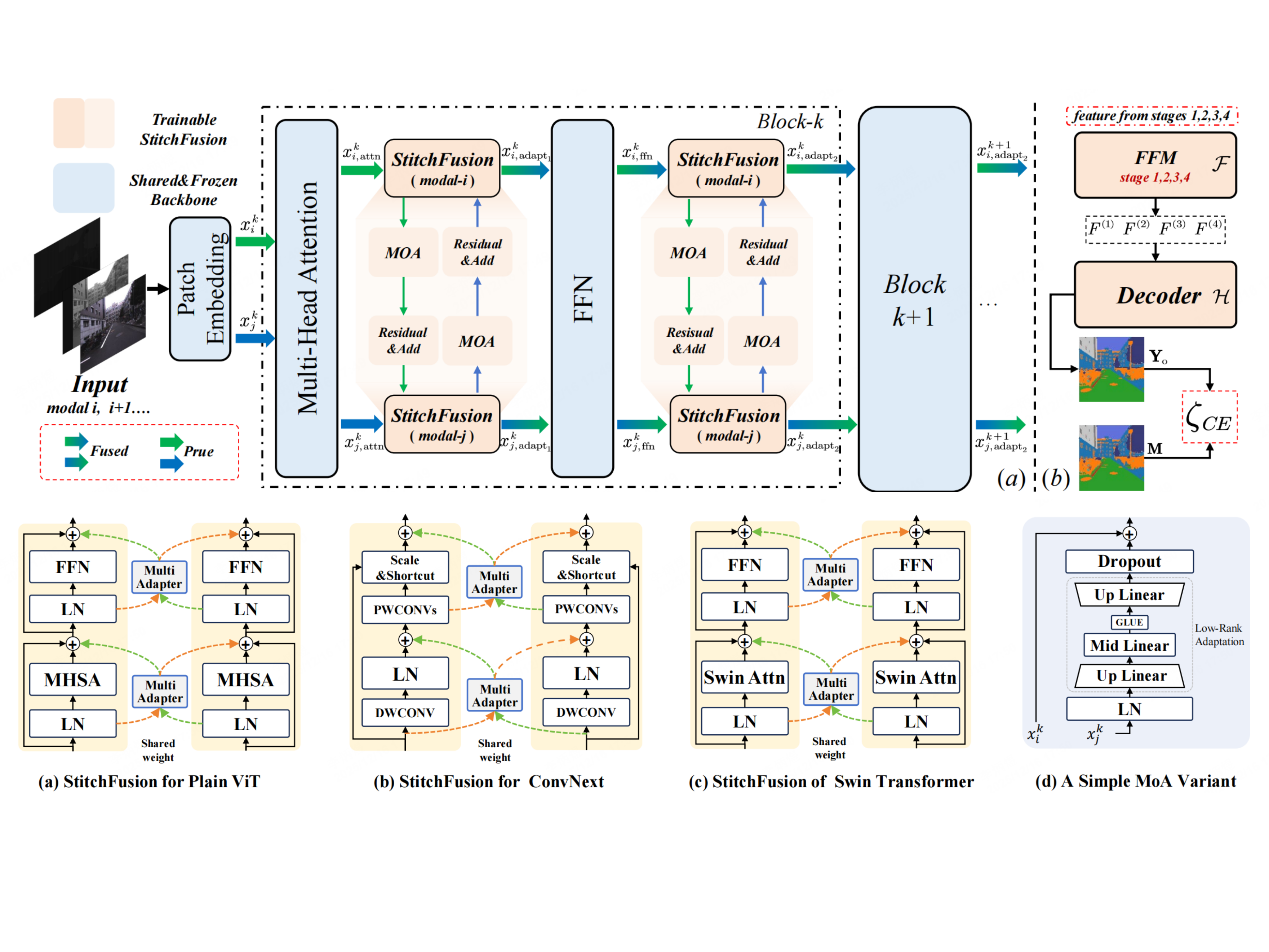
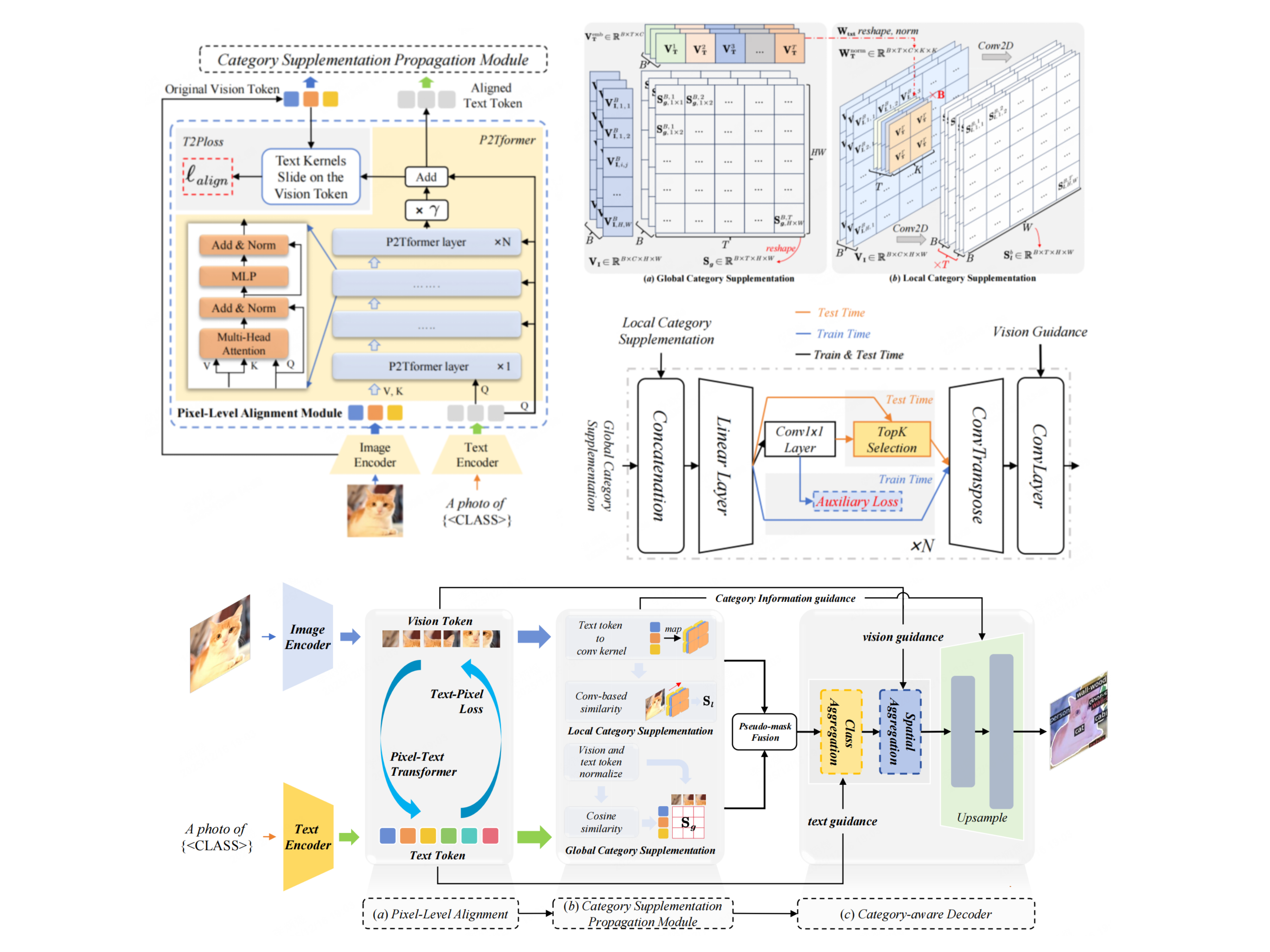
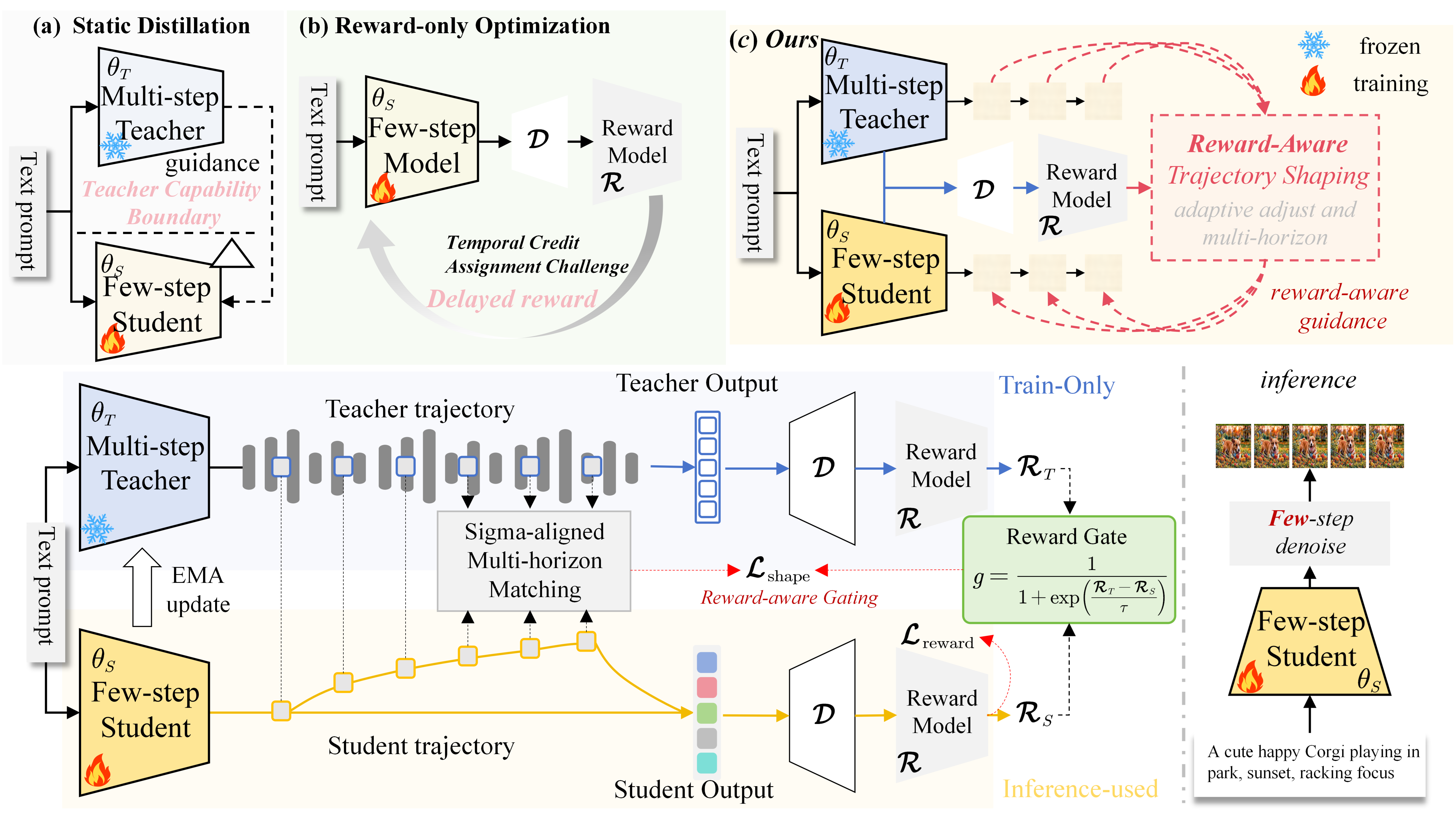
MTRefSeg introduces Multi-temporal Referring Segmentation (MTRS), where models compare temporally related images and segment the language-described changed region. The work builds MTRefSeg-21K with 21K bi-image-text-mask annotations and proposes MTRefSeg-R1, a change-aware LVLM trained by vision-only temporal pretraining followed by referring multi-temporal fine-tuning.